В магазине электроники раз в месяц проводится распродажа. Из всех товаров выбирают К товаров с самой большой ценой и делают на них скидку в 20%, затем ещё М товаров с самой большой ценой и делают на них скидку 10%. По заданной информации о цене каждого из товаров и количестве товаров, на которые будет скидка, определите цену самого дорогого товара, не участвующего в распродаже, а также целую часть от суммы всех скидок.
Входные и выходные данные. В первой строке входного файла находятся три числа, записанные через пробел: N — общее количество цен (натуральное число, не превышающее 10 000), К — количество товаров со скидкой 20% и М — количество товаров со скидкой 10%. В следующих N строках находятся значения цены каждого из товаров (все числа натуральные, не превышающие 10 000), каждое в отдельной строке. Запишите в ответе два числа: сначала цену самого дорогого товара, не участвующего в распродаже, а затем целую часть от суммы всех скидок.


При проведении эксперимента заряженные частицы попадают на чувствительный экран, представляющий из себя матрицу размером 10 000 на 10 000 точек. При попадании каждой частицы на экран в протоколе фиксируются координаты попадания: номер ряда (целое число от 1 до 10 000) и номер позиции в ряду (целое число от 1 до 10 000).
Точка экрана, в которую попала хотя бы одна частица, считается светлой, точка, в которую ни одна частица не попала, — тёмной.
Вам необходимо по заданному протоколу определить номер ряда с наибольшим количеством светлых точек в нечётных позициях. Если таких рядов несколько, укажите минимально возможный номер.
Входные данные
Первая строка входного файла содержит целое число N — общее количество частиц, попавших на экран. Каждая из следующих N строк содержит 2 целых числа: номер ряда и номер позиции в ряду.
В ответе запишите два целых числа: сначала наибольшее количество светлых точек в нечётных позициях одного ряда, затем — номер ряда, в котором это количество встречается.
Вариант 1. Задача с магазином и деталями.

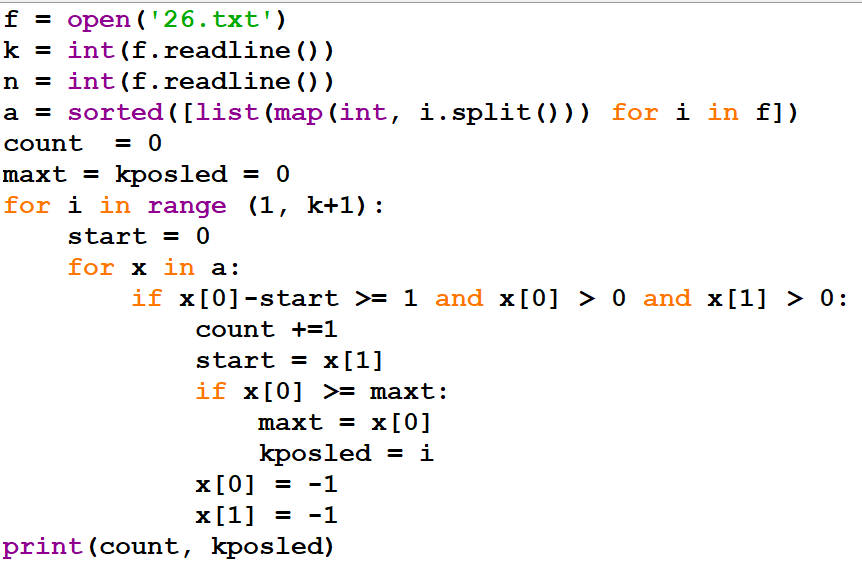
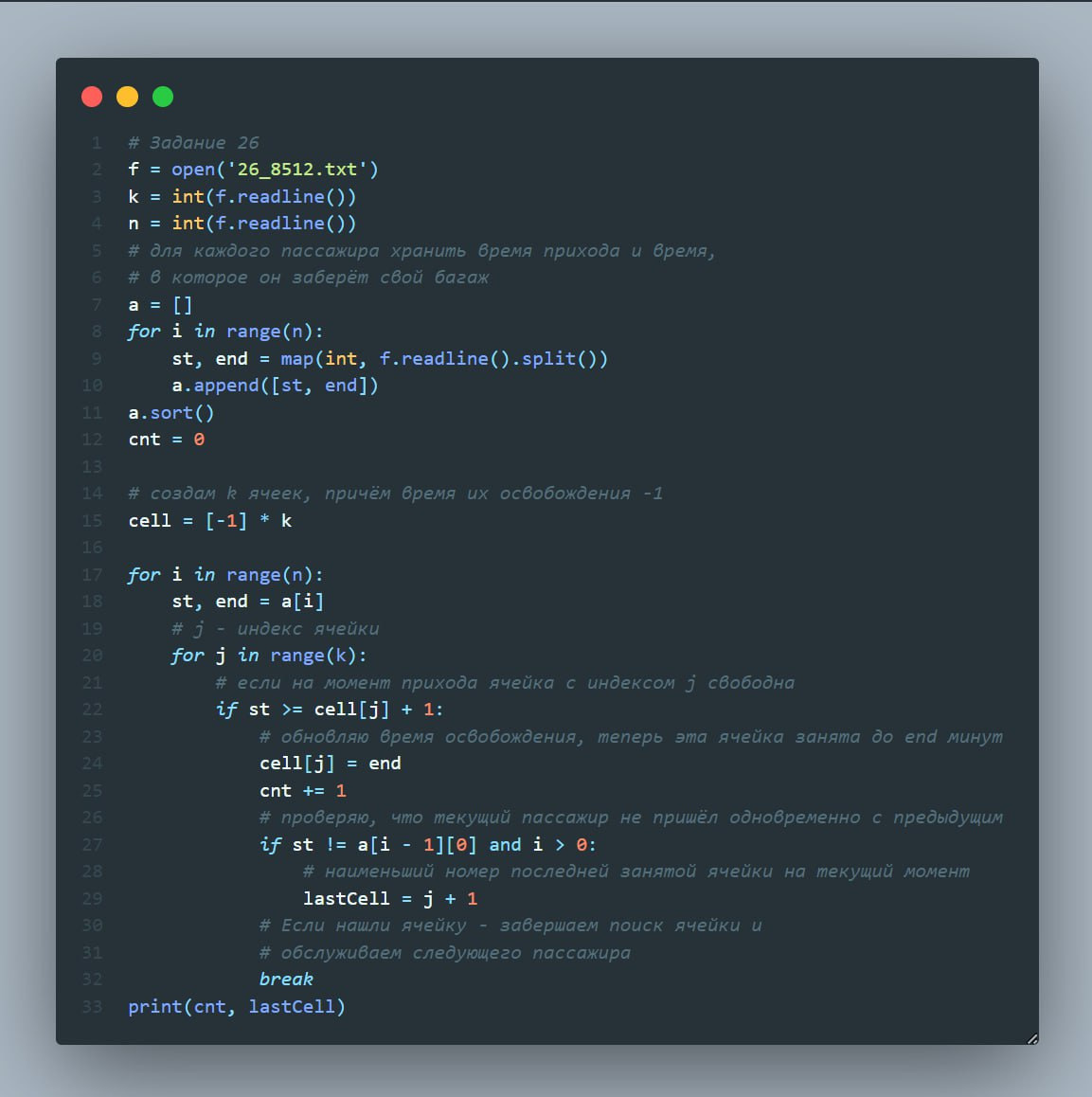
В аэропорту есть камера хранения из K ячеек, которые пронумерованы с 1. Принимаемый багаж кладется в свободную ячейку с минимальным номером. Известно время, когда пассажиры сдают и забирают багаж (в минутах с начала суток). Ячейка доступна для багажа, начиная со следующей минуты, после окончания срока хранения. Если свободных ячеек не находится, то багаж не принимается в камеру хранения.
Найдите количество багажей, которое будет сдано в камеры за 24 часа и номер ячейки, в которую сдаст багаж последний пассажир.
Входные данные
В первой строке входного файла находится число K — количество ячеек в камере хранения, во второй строке файла число N — количество пассажиров, сдающих багаж (натуральное число, не превышающее 1000).
Каждая из следующих N строк содержит два натуральных числа, не превышающих 1440: время сдачи багажа и время выдачи багажа.
Выходные данные
Программа должна вывести два числа: количество сданных в камеру хранения багажей и номер ячейки, в которую примут багаж у последнего пассажира, который сможет сдать багаж.

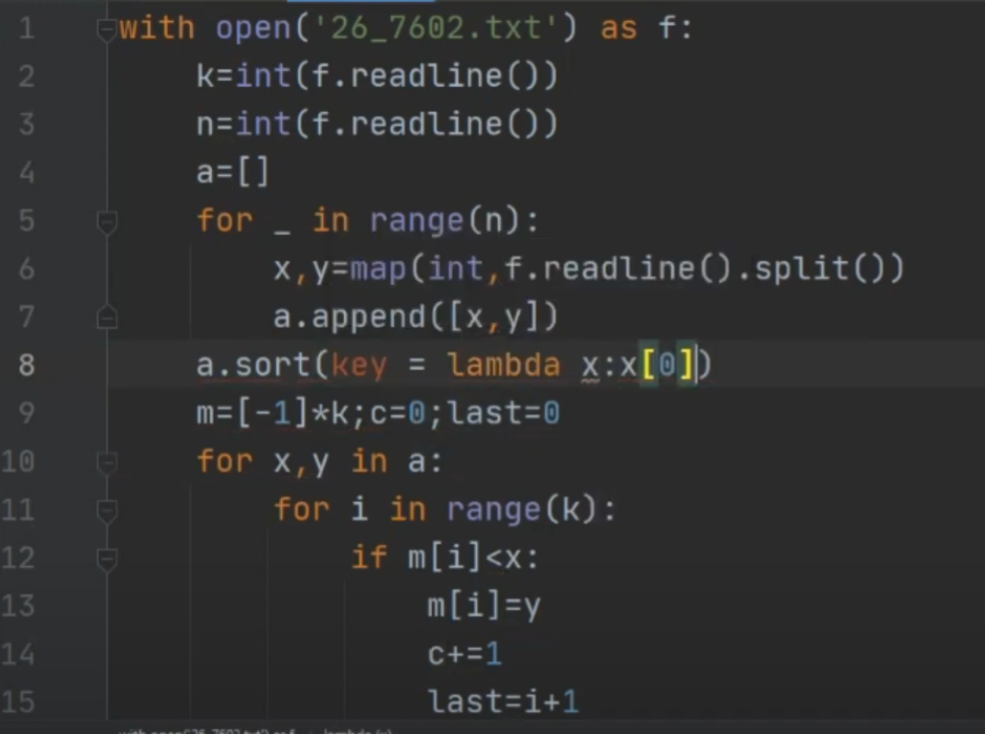
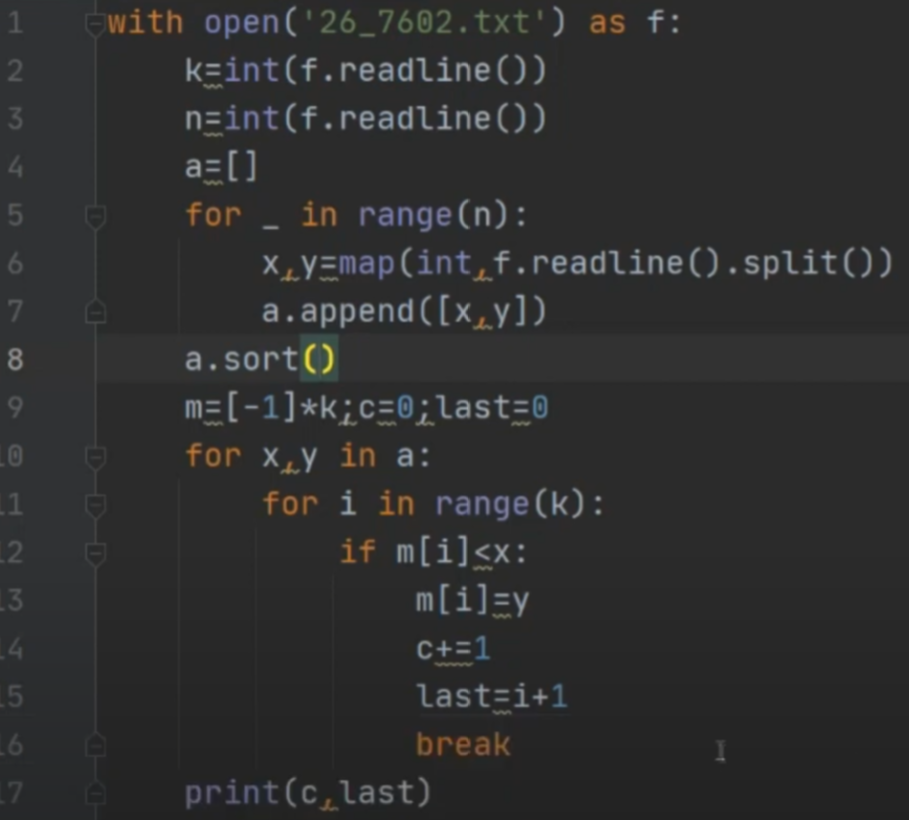
В лесополосе осуществляется посадка деревьев. Причем саженцы высаживают рядами на одинаковом расстоянии.
Через какое-то время осуществляется аэросъемка, в результате которой определяется, какие саженцы прижились. Необходимо определить ряд с максимальным номером, в котором есть подряд ровно 11 неприжившихся саженцев, при условии, что справа и слева от них саженц прижились.
В ответе запишите сначала наибольший номер ряда, затем наименьший номер из неприжившихся мест.
Входные данные:
В первой строке входного файла 26.txt находится число N — количество занятых мест (натуральное число, не превышающее 10 000). Каждая из следующих N строк содержит два натуральных числа, не превышающих 100 000: номер ряда и номер заного места.
Выходные данные:
Два целых неотрицательных числа: максимальный номер ряда, где нашлись обозначенные в задаче места, и минимальный номер подходящего места.
В магазине для упаковки подарков есть N кубических коробок. Самой интересной считается упаковка подарка по принципу матрёшки — подарок упаковывается в одну из коробок, та в свою очередь в другую коробку и т. д.
Одну коробку можно поместить в другую, если длина её стороны хотя бы на 3 единицы меньше длины стороны другой коробки. Определите наибольшее количество коробок, которое можно использовать для упаковки одного подарка, и максимально возможную длину стороны самой маленькой коробки, где будет находиться подарок. Размер подарка позволяет поместить его в самую маленькую коробку.
Входные данные
В первой строке входного файла находится число N — количество коробок в магазине (натуральное число, не превышающее 10 000). В следующих N строках находятся значения длин сторон коробок (все числа натуральные, не превышающие 10 000), каждое — в отдельной строке.
Запишите в ответе два целых числа: сначала наибольшее количество коробок, которое можно использовать для упаковки одного подарка, затем максимально возможную длину стороны самой маленькой коробки в таком наборе.

В аэропорту есть камера хранения из K ячеек, которые пронумерованы с 1. Принимаемый багаж кладется в свободную ячейку с минимальным номером. Известно время, когда пассажиры сдают и забирают багаж (в минутах с начала суток). Ячейка доступна для багажа, начиная со следующей минуты, после окончания срока хранения. Если свободных ячеек не находится, то багаж не принимается в камеру хранения.
Найдите количество багажей, которое будет сдано в камеры за 24 часа и номер ячейки, в которую сдаст багаж последний пассажир.
Входные данные
В первой строке входного файла находится число K — количество ячеек в камере хранения, во второй строке файла число N — количество пассажиров, сдающих багаж (натуральное число, не превышающее 1000). Каждая из следующих N строк содержит два натуральных числа, не превышающих 1440: время сдачи багажа и время выдачи багажа.
Выходные данные
Программа должна вывести два числа: количество сданных в камеру хранения багажей и номер ячейки, в которую примут багаж у последнего пассажира, который сможет сдать багаж.

Вариант 2.
В текстовом файле записан набор натуральных чисел, не превышающих 109. Гарантируется, что все числа различны. Необходимо определить, сколько в наборе таких пар чётных чисел, что их среднее арифметическое тоже присутствует в файле, и чему равно наибольшее из средних арифметических таких пар.
Входные данные Первая строка входного файла содержит целое число? — общее количество чисел в наборе. Каждая из следующих? строк содержит одно число.
В ответе запишите два целых числа: сначала количество пар, затем наибольшее среднее арифметическое.
# Линейный поиск (работает долго)
data = list(map(int, open(r'./Data/26/ИН2010401.txt').read().splitlines()))[1:]
k, mx = 0, 0
for i in range(len(data)-1):
if data[i] % 2 == 0:
for j in range(i + 1, len(data)):
if data[j] % 2 == 0:
sr = (data[i] + data[j]) // 2
if sr in data:
k, mx = k + 1, max(mx, sr)
print(k, mx)
# Бинарный поиск
a = list(map(int, open(r'./Data/26/ИН2010401.txt').read().splitlines()))[1:]
a.sort()
lsts = []
for i in range(len(a) — 1):
for j in range(i + 1, len(a)):
if a[i] % 2 == 0 and a[j] % 2 == 0:
s = (a[i] + a[j]) // 2
L = i
R = j + 1
while L < R — 1:
C = (R + L) // 2
if s < a[C]:
R = C
else:
L = C
if a[L] == s:
lsts.append(s)
print(len(lsts), max(lsts))
Вариант 3.
Продавец предоставляет покупателю, делающему большую закупку, скидку по следующим правилам:
— на каждый второй товар стоимостью больше 50 рублей предоставляется скидка 25%;
— общая стоимость покупки со скидкой округляется вверх до целого числа рублей;
— порядок товаров в списке определяет продавец и делает это так, чтобы общая сумма скидки была наименьшей.
По известной стоимости каждого товара в покупке необходимо определить общую стоимость покупки с учётом скидки и стоимость самого дорогого
товара, на который будет предоставлена скидка.
f = open('inf_22_10_20_26.txt')
n = int(f.readline())
s=0
m=[]
for i in range (n):
a=int(f.readline())
if a<51:
s=s+a
else:
m.append(a)
m.sort()
for i in range(len(m)//2):
m[i] = m[i] * 0.75
print(round(s+sum(m)), round(m[i]/0.75))
____________________________________________________________
point=list(list(map.int, string.split())) for string in map(str, open('26.txt').read().splitlines())
n=point[0]
point.pop(0)
point=sorted(point)
maxpoint=0
minpow=0
countpoint=1
for i in range(1,len(point)):
if point[i] == pont[i-1]:
continue
if point[i][o]==point[i-1][0] and point[i-1][1]:
countpoint+=1
if countpoint>maxpoint:
maxpoint=countpoint
minrow=point[i][0]
else:
countpoint=1
print(maxpoint, minrow)
Вариант 4.
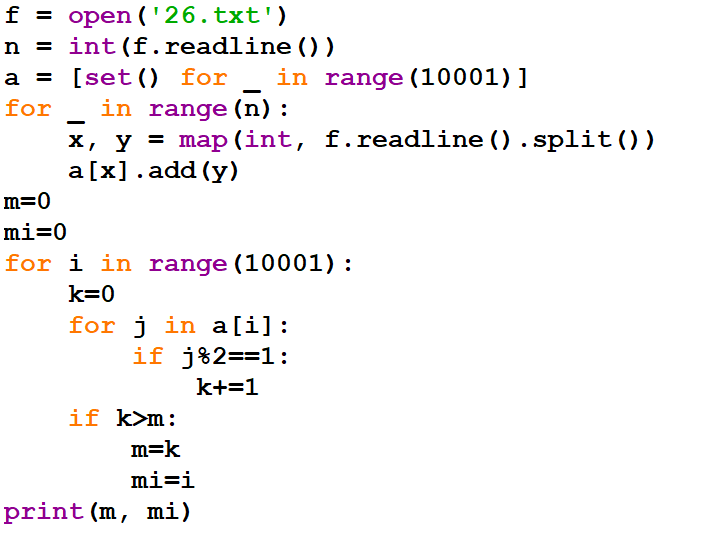
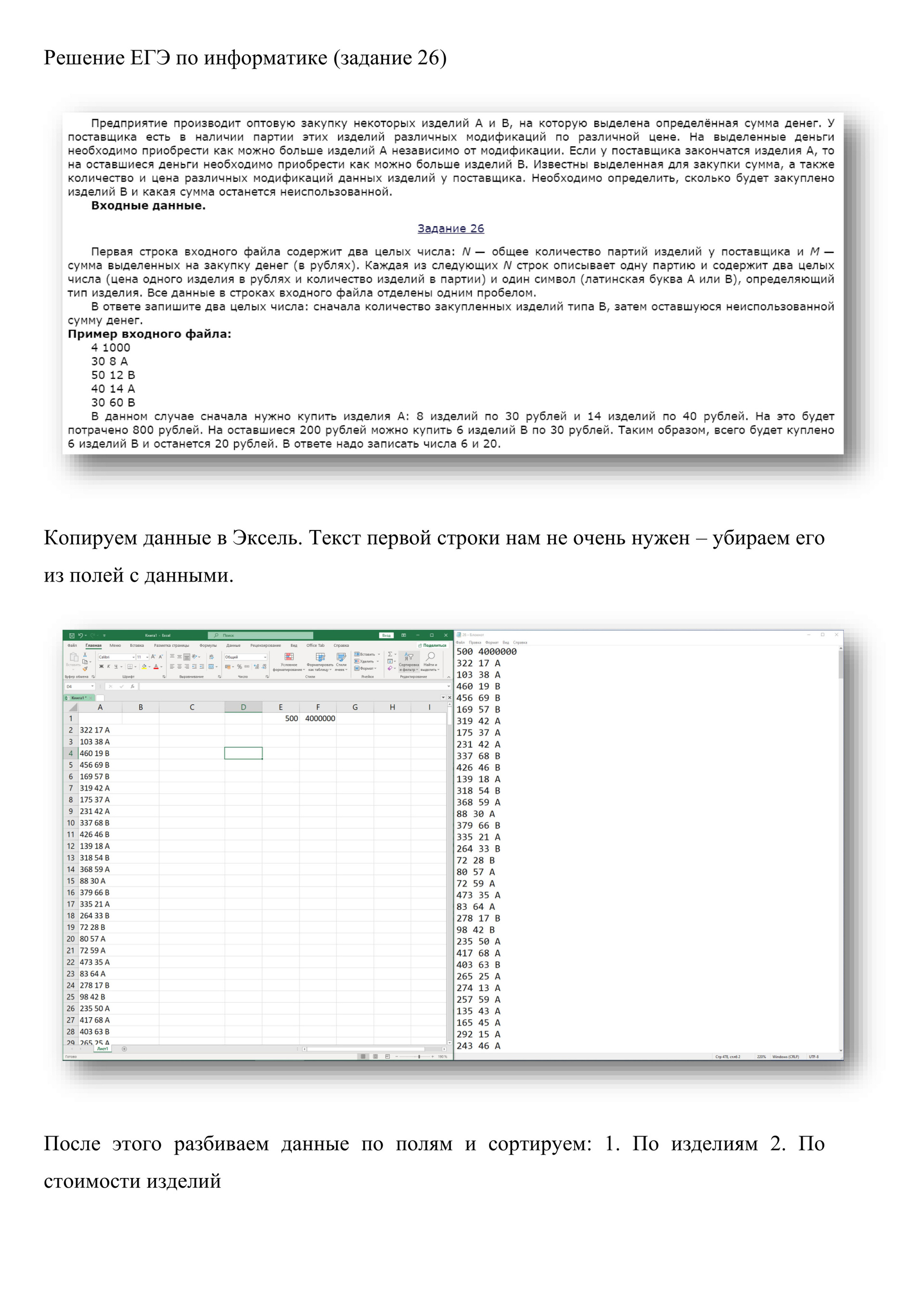
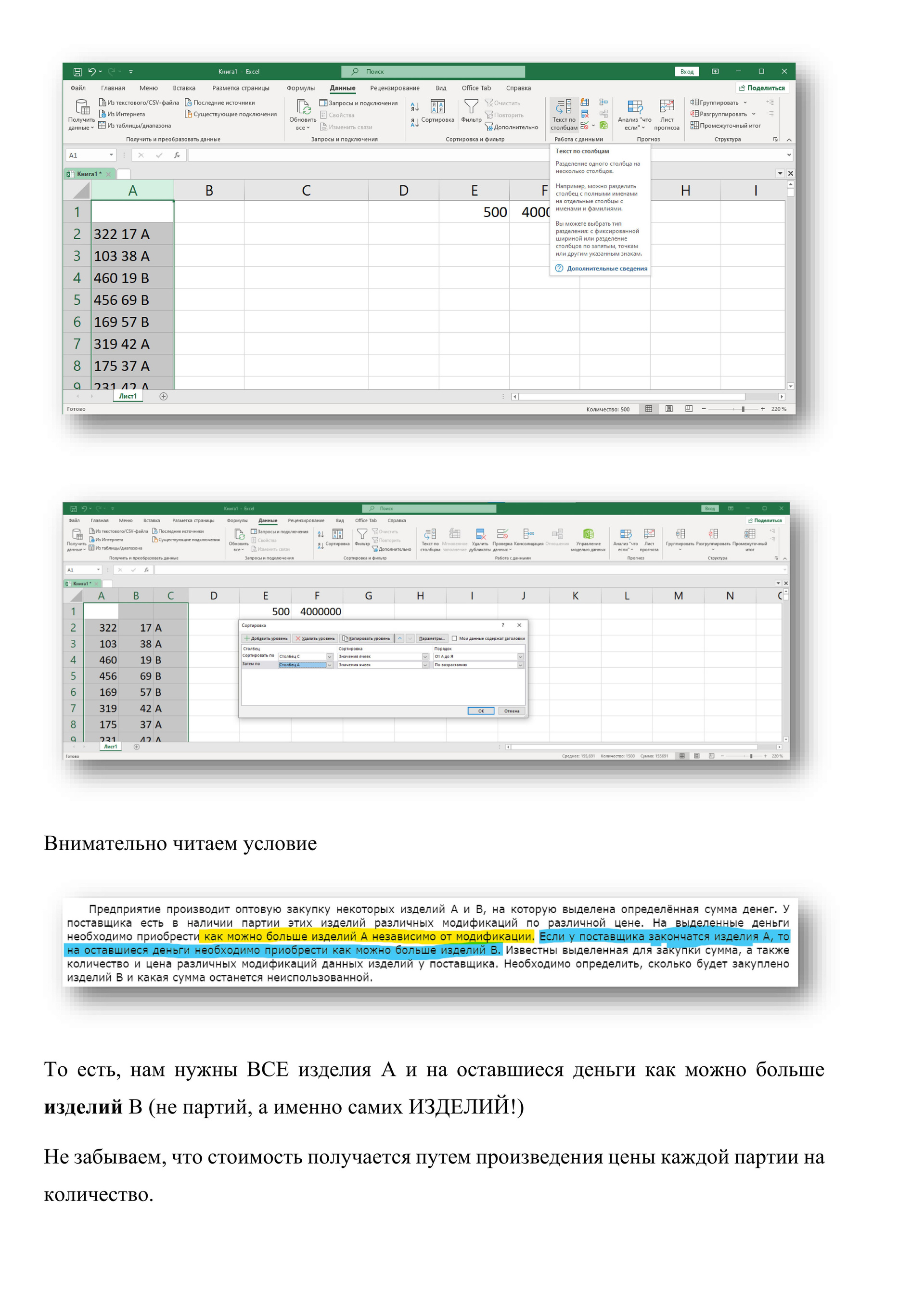
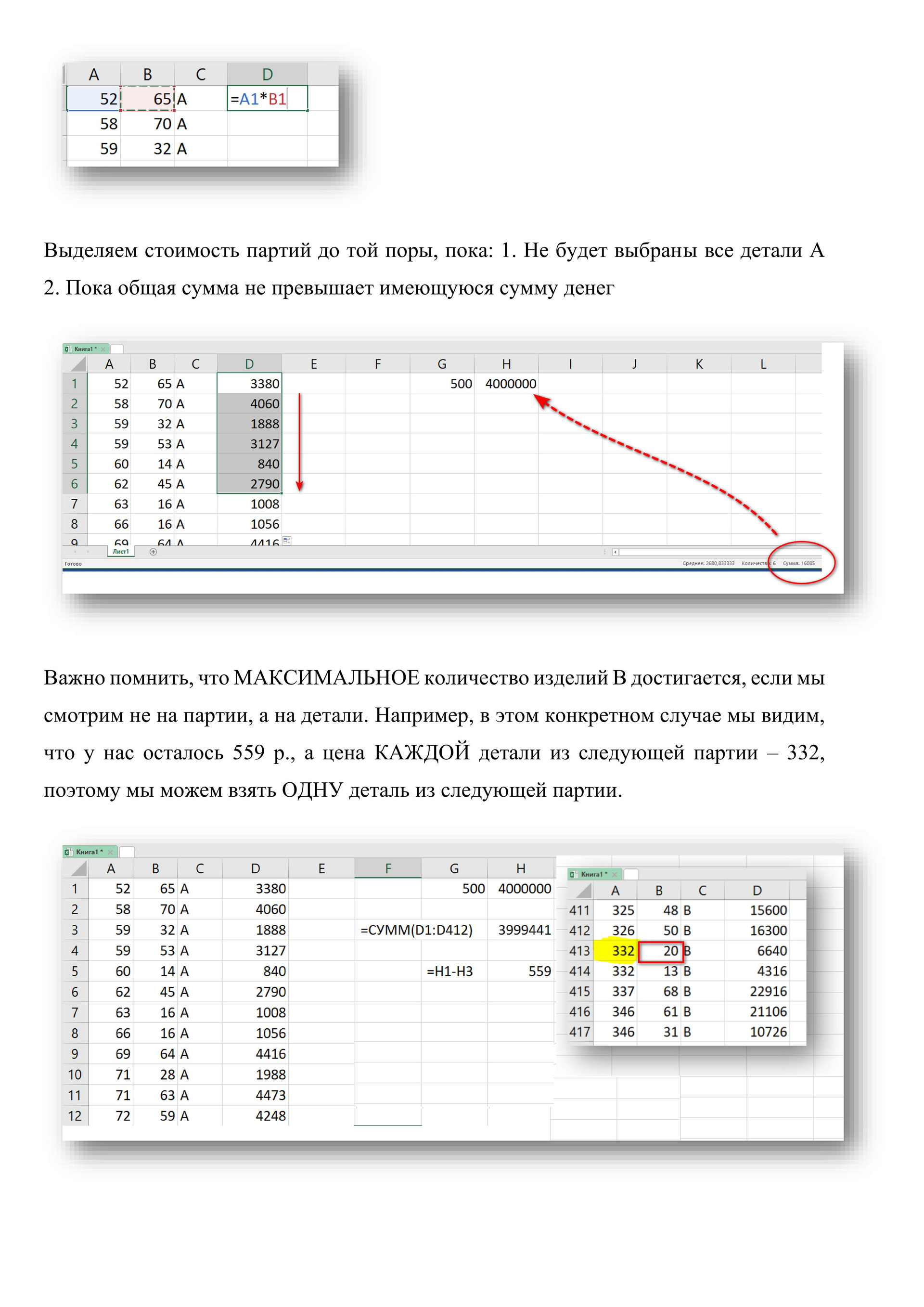
# Предприятие производит оптовую закупку некоторых изделий A и B, на которую выделена определённая сумма денег. У поставщика есть в наличии партии этих изделий различных модификаций по различной цене. На выделенные деньги необходимо приобрести как можно больше изделий A независимо от модификации.
Если у поставщика закончатся изделия A, то на оставшиеся деньги необходимо приобрести как можно больше изделий B. Известны выделенная для закупки сумма, а также количество и цена различных модификаций данных изделий у поставщика. Необходимо определить, сколько будет закуплено изделий B и какая сумма
останется неиспользованной.
f = open('26 (3).txt')
n, m = map(int, f.readline().split())
a=[]
for i in range (n):
x, y, z = f.readline().split() # x — цена y — количество z- тип товара
a.append((z, int(x), int(y)))
a.sort(key = lambda x: (x[0], x[1]))
xsum, countb = 0,0
for x in a:
if xsum +x[1] >m: break
for i in range(1,x[2] +1):
if xsum +x[1] <= m:
xsum = xsum + x[1]
if x[0] =='B': countb=countb+1
print(countb, m — xsum)
Вариант 5.
В текстовом файле записан набор натуральных чисел, не превышающих 109.
Гарантируется, что все числа различны. Необходимо определить, сколько в наборе таких пар чётных чисел, что их среднее арифметическое тоже присутствует в файле,
и чему равно наибольшее из средних арифметических таких пар.
Входные данные
Первая строка входного файла содержит целое число N — общее количество чисел в наборе. Каждая из следующих N строк содержит одно число.
f = open(‘stat17032021.txt’)
n = int(f.readline())
e = []
o = set()
for i in range(n):
x = int(f.readline())
if x % 2 == 0:
e.append(x)
else:
o.add(x)
k = 0
m = 0
ee = set(e)
for i in range(len(e)-1):
for j in range(i+1, len(e)):
sr = (e[i] + e[j]) // 2
if sr in ee or sr in o:
k += 1
if sr > m:
m = sr
print(k, m)
Вариант 6.
Системный администратор раз в неделю создаёт архив пользовательских файлов. Однако объём диска, куда он помещает архив, может быть меньше, чем суммарный объём архивируемых файлов. Известно, какой объём занимает файл каждого пользователя.
По заданной информации об объёме файлов пользователей и свободном объёме на архивном диске определите максимальное число пользователей, чьи файлы можно сохранить в архиве, а также максимальный размер имеющегося файла, который может быть сохранён в архиве, при условии, что сохранены файлы максимально возможного числа пользователей.
f=open(‘27883.txt’)
s, n=map(int, f.readline().split())
sv=sorted(map(int, f))
sumn, c=0,0
for i in range(len(sv)):
if sumn + sv[i]<=s:
sumn= sumn+sv[i]
c=c+1
nf=s-sumn+sv[c-1:][0]
while nf not in sv:
nf=nf+1
print(c, nf)
Вариант 7.
# Во многих компьютерных системах текущее время хранится в формате «UNIX-время» — количестве секунд от начала суток 1 января 1970 года.
# В одной компьютерной системе проводили исследование загруженности. Для этого в течение месяца с момента UNIX-времени 1633046400 фиксировали и заносили в базу данных моменты старта и финиша всех процессов, действовавших в этой системе.
# Вам необходимо определить, какое наибольшее количество процессов выполнялось в системе одновременно на неделе, начавшейся в момент UNIX-времени 1633305600, и в течение какого суммарного времени (в секундах) выполнялось такое наибольшее количество процессов.
input= open('26 (1).txt').readline
n=int(input())
L=[]
for i in range(n):
st, en = map(int, input().split())
L.append((st, 1))
if en==0: en = 2000000000
L.append((en, -1))
L.sort()
mxk=dt=k=0
w0=1633305600; w1=w0+7*24*3600
for t, dk in L:
k += dk
if w0<k<w1:
if k>mxk: mxk, dt = k, 0
if k-dk==mxk: dt +=t-t0
t0=t
print(mxk, dt)
Вариант 8.
Системный администратор раз в неделю создаёт архив пользовательских файлов. Однако объём диска, куда он помещает архив, может быть меньше, чем суммарный объём архивируемых файлов.
Известно, какой объём занимает файл каждого пользователя. По заданной информации об объёме файлов пользователей и свободном объёме на архивном диске определите максимальное число пользователей, чьи файлы можно сохранить в архиве, а также максимальный размер имеющегося файла, который может быть сохранён в архиве, при условии, что сохранены файлы максимально возможного числа пользователей.
f = open('26 (2).txt')
data = f.readlines() # массив строк , readlines
s = data[0].split() # ['8200', '970']
s = int(s[0]) # 8200 — объем св места на диске
del(data[0]) # первая строка больше не нужна, удаляем ее
for i in range(0, len(data)): # цикл для преобразования в int
data[i]=int(data[i])
data=sorted(data) # сортируем полученный массив для удобства работы
summa = 0
for count in range (0,len(data)):
if summa + data[count] > s: break # если сумма больше — прерываем цикл
summa += data[count] # формируем сумму, добавляя отсортированные элементы
# как только сумма превысила s, произойдёт выход из цикла по оператору break,
#, а в переменной count останется количество добавленных значений
print (count) # макс число файлов в архиве
# вычисляем запас, который мы можем уменьшить с помощью замены одного выбранного значения на другое:
zapas = s — summa
# теперь выбираем из массива данных те значения, которые могут быть выбраны:
# разность между таким значением и наибольшим выбранным элементом data[count-1] должна быть не больше, чем zapas:
for i in range (0,len(data)):
if data[i] — data[count-1] <= zapas:
itog = data[i]
print(itog) # максимальный размер файла
Вариант 9.
В магазине электроники раз в месяц проводится распродажа. Из всех товаров выбирают K товаров с самой большой ценой и делают на них скидку в 20%. По заданной информации о цене каждого из товаров и количестве товаров, на которые будет скидка, определите цену самого дорогого товара, не участвующего в распродаже, а также целую часть от суммы всех скидок.
f = open('26-k1.txt')
data = f.readlines()
s = data[0].split()
nPrice=int(s[0]) # количество цен
k = int(s[1]) # количество товаров с самой большой ценой
del(data[0])
for i in range (0, len(data)): # переводим в целые числа
data[i] = int(data[i])
print(data)
data = sorted(data, reverse=True) # или data.sort(reverse = True)
summa = 0
for i in range(0,k):
summa+=data[i]*0.2 # 10000 10000 10000
print(data[k], int(summa)) # data[k] — самый дорогой товар, так как k уже не входит в счетчик цикла
Вариант 10.
# Предприятие производит оптовую закупку некоторых изделий A и B, на которую выделена определённая сумма денег. У поставщика есть в наличии партии этих изделий различных модификаций по различной цене. На выделенные деньги необходимо приобрести как можно больше изделий B независимо от модификации.
# Если у поставщика закончатся изделия B, то на оставшиеся деньги необходимо приобрести как можно больше изделий A. Известны выделенная для закупки сумма, а также количество и цена различных модификаций данных изделий у поставщика.
# Необходимо определить, сколько будет закуплено изделий A и какая сумма останется неиспользованной.
f = open('26 (4).txt')
n, m = map(int, f.readline().split())
a=[]
for i in range (n):
x, y,z = f.readline().split() # x — цена y — количество z- тип товара
a.append((z, int(x), int(y)))
a.sort(key = lambda x: (x[0]=='A', x[1]))
xsum, counta = 0,0
for x in a:
if xsum +x[1] >m: break
for i in range(1,x[2] +1):
if xsum +x[1] <= m:
xsum = xsum + x[1]
if x[0] =='A': counta=counta+1
print(counta, m — xsum)
Материалы ученикам

Хорошее поведение
Обязательные требования при работе в компьютерном классе
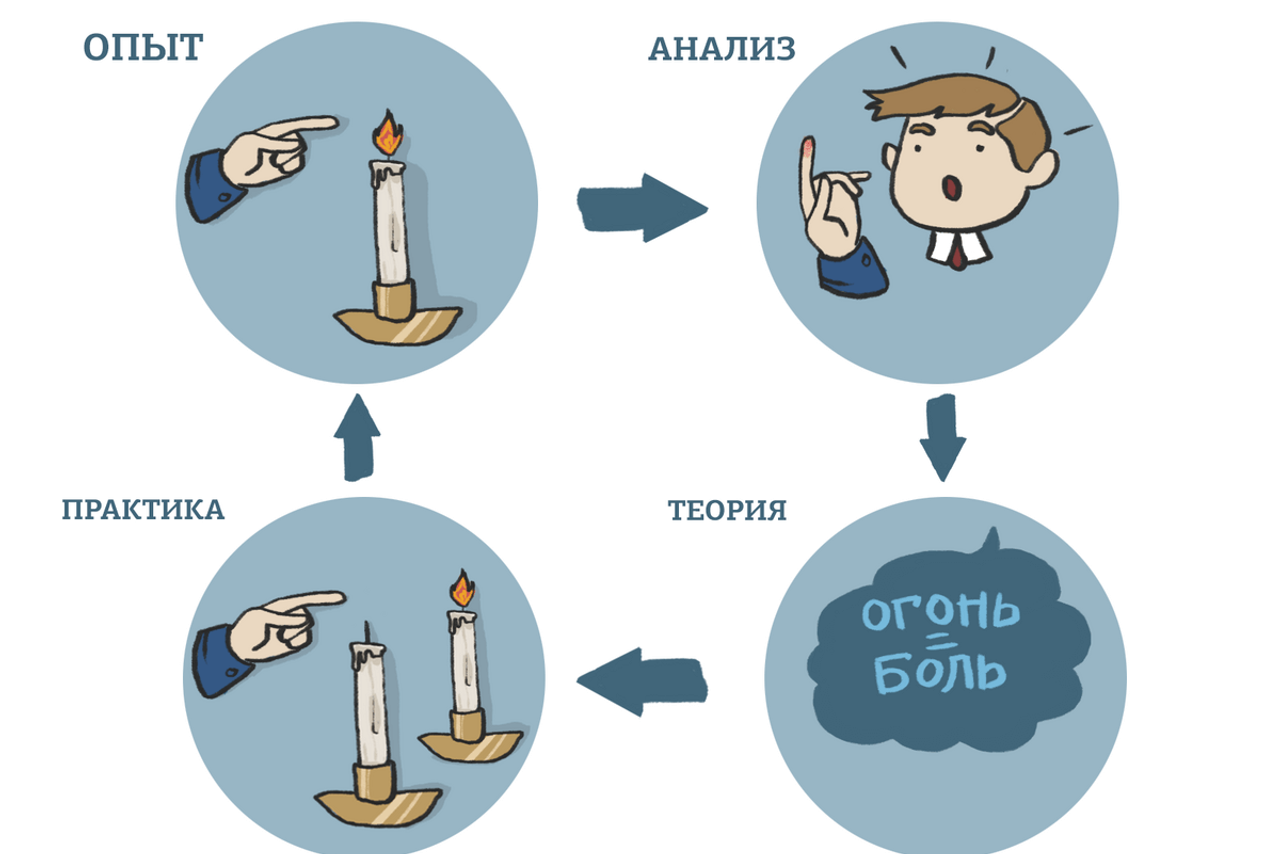
Практика без теории — путь в никуда

Правильный подход к выполнению домашнего задания и мои требования

О воспитании и подготовке домашнего задания
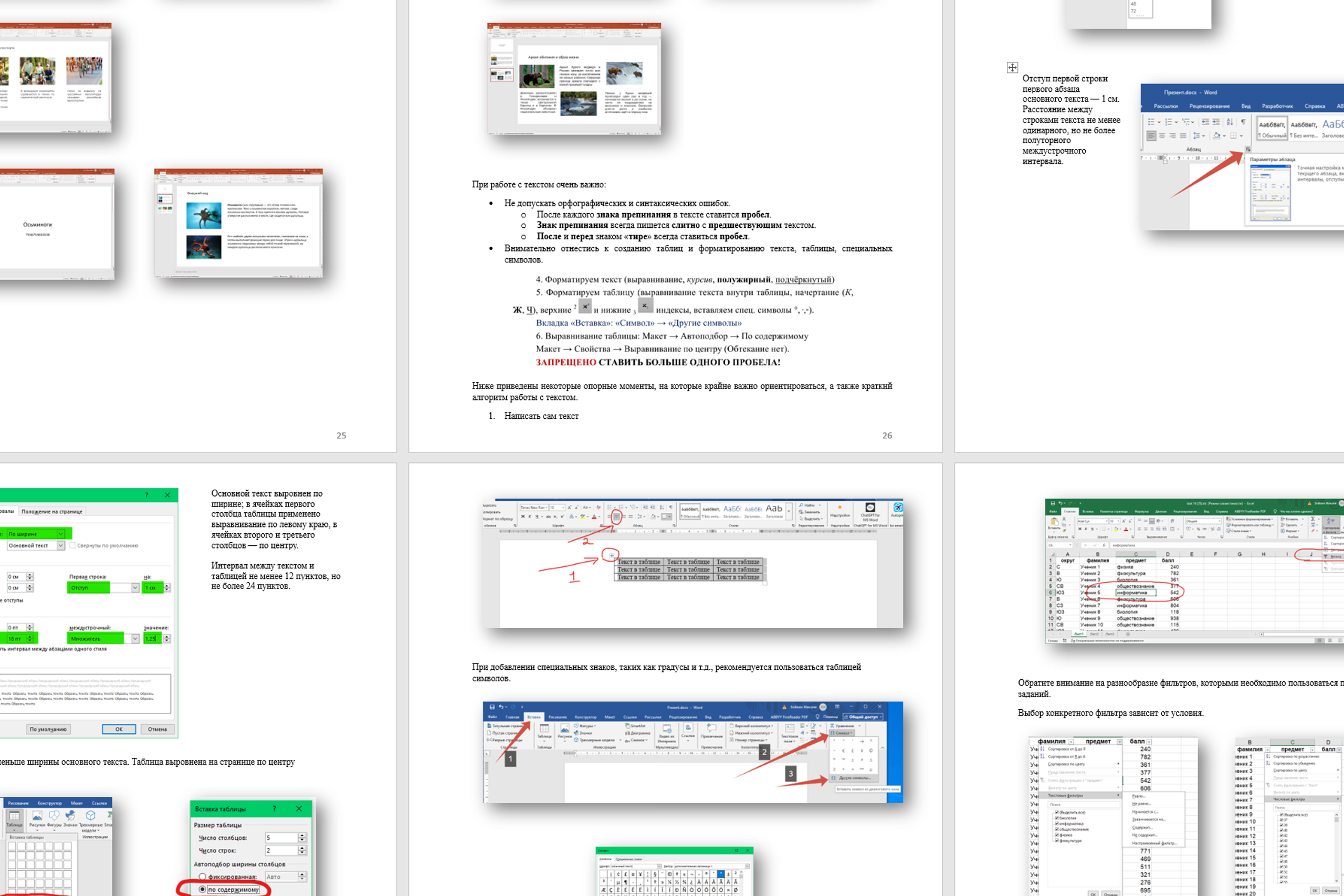
Примеры решений и указаний к заданиям ОГЭ по информатике 2025. Используется, как база, вариант 2025 года.